HiF8:为大模型时代而生的新一代8比特浮点数据格式
HiFloat

在刚刚结束的 2025 全球计算大会(CGC)智能计算分论坛上,华为技术有限公司 2012 实验室高级研究员程楹楹带来了关于新型 8 比特浮点数据格式 HiF8 的重磅分享。随着 AI 模型规模持续扩张,当前主流的浮点数据格式已难以满足业界对计算能效的要求,而基于传统思路设计的低精度浮点数据格式又面临着动态范围不足、计算冗余等挑战,HiF8 的推出为大模型训练与推理提供了更契合 AI 数据特征的创新解法。

HiF8 是什么?
在 AI 大模型训练推理基础数据格式迈入 8 比特的时代背景下,HiF8 应运而生。程楹楹指出,在 CNN 时代,FP16 与 BF16 并行使用,但随着大模型权重分布日益分散,对动态范围的需求显著提升,BF16 逐渐占据主导。而进入 8 比特阶段,如何在窄动态范围下保持稳定性,成为新的挑战。
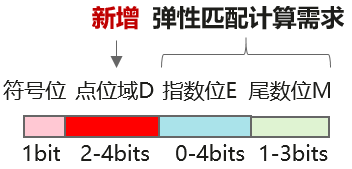
HiF8 在数据格式上的创新在于引入可变长点位域 Dot,基于该域的取值,数据所表达的阶码范围和数据精度可以灵活设定,从而使模型训练/推理所用的数据可以根据具体的计算需求选取更合适的阶码或精度,减少量化频次。
该设计中,HiF8 能表达的综合阶码范围从通常的 -15, +15 扩展到 -22, +15,共 38 个阶码,几乎达到 FP16 的 40 个综合阶码表达能力,显著扩大了动态范围,使其在大模型训练与推理场景中具备更强的数值表达能力和更稳定的计算过程。
正如程研究员所言:“HiF8 兼顾了精度和动态范围,为神经网络的训练和推理提供了更全面的 8 比特数据格式表达。”
HiF8 Scaling 策略探索
在低精度训练中,Scaling(缩放)策略是维持数值稳定性的关键环节。其核心思想是通过一个缩放因子,将权重或激活值映射至可表示的数值区间内,以避免溢出或梯度失真。
HiF8 因为具有更大的动态范围(38 个阶码)从而可以减少对缩放因子的刷新,大幅减少计算负载。总体上,HiF8 的 Scaling 策略实现了**“低频更新、高稳定性、高吞吐”**的平衡,为未来大模型训练提供了更具工程价值的路径。
HiF8 训练实践
在 DeepSeek-3B 模型上进行 15B Tokens 的预训练实验中,HiF8 与 FP8 在 Loss 收敛曲线上几乎重合,HiF8 表现更为平滑稳定。
在 Olmo-1B 模型上,团队尝试了 80B Tokens 的预训练,对比 80B BF16 基线,任务平均准确率相差不到 1%,几乎无损;进一步对比 3T 数据量的训练精度,HiF8 表现接近,证明其在大规模预训练中的精度可用性与收敛稳定性。
总结与展望
综合来看,HiF8 兼顾精度与动态范围,为大模型训练与推理提供了能力更全面的 8-bit 单数据格式表达,并在 DeepSeek-3B(15B Tokens)与 Olmo-1B(80B Tokens)模型中分别验证了 HiF8 预训练的收敛稳定性与精度可用性。
随着 HiF8 训推仿真工具开放给 GCC,GCC 智算产发委数据格式工作组将选择合适的产业伙伴,面向实际应用模型验证 HiF8 的训推能效,让伙伴的模型、应用在该特性产品化的第一时间同步上市。
敬请锁定 GCC IP 栏目 CompuWave!GCC 智算产业发展委员会将持续带来「HiF8」系列专题分享,关于 HiF8 数据格式的深度解析、技术剖析系列文章及业界专家的独家供稿将持续发布,共同探讨低精度计算的未来方向!
更多 HiF8 联创招募、进展等信息可联系 GCC 智算产发委执行秘书长熊华(xionghua@gccorg.com)获取。
汇聚全球专家洞见,碰撞多元思维火花
聚焦计算前沿突破,捕捉技术创新脉搏
这里既有深度产业观察、趋势研判,
也有前沿技术探索、创新路径解析
让每一份专业表达与先锋探索,
都能共振行业、影响未来现在,
加入 CompuWave
与全球计算先锋共探技术边界,共逐蓝海征程